Machine learning, or statistical learning, is an area of statistical modeling and artificial intelligence.
Machine learning sets out to recognize structures that are often too difficult to detect or measure manually from data. Once you have these structures, you can try to classify individuals, objects, forecast the value of a variable at a specific horizon or explain the appearance or absence of a characteristic.
Examples of machine learning usage are to:
- forecast a particular product’s sales over the next three months on the basis of its past sales
- create a customer base classification on the basis of sociodemographic characteristics and past purchases
- assign a rating to an individual indicating whether or not (s)he is about to unsubscribe from a product
- automatically recognize a handwritten figure or a face
Once more than one or two variables are involved, it becomes difficult to discern structures in data with the naked eye. This is where statistical learning or machine learning come into their own. The same applies when the number of individuals (or observations) increases.
Let’s take an example… we want to determine whether an individual in a shoe shop database will click on the link in a promotional mailshot. To do this, we first examine the records. Here is a part of them:
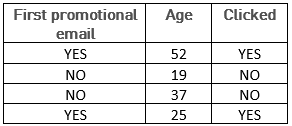
Here the observations, or individuals, are the database contacts. They are not necessarily brand customers. The explanatory variables, indicators or characteristics, are age, and the fact that it is or is not the first email sent.
Here the variable to be explained, or the target variable, is whether or not a customer has clicked on the email link. We know the value of this variable from the records. The goal is to deduce, precisely from this record that we call learning population, the target variable value for new individuals in a test population. The aim is to find the rule that will make the fewest mistakes on this target variable. This rule will be created by a complex machine learning algorithm in most cases and will be generally very difficult, if not impossible, to explain.
In this example, we can manually guess a simple and simplistic structure here, which would be: “If it is the first promotional email sent to a customer, the individual clicks”. However, if we consider a bigger database, we realize that this very simple rule is prone to error:
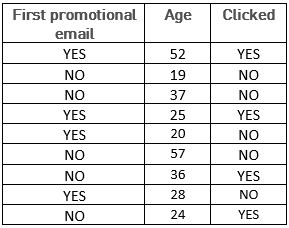
We then realize that the real structure of the data cannot be deduced from age and knowing whether or not it is the first email, but that we need additional data, such as the individual’s gender, whether (s)he has recently purchased or not, whether or not (s)he clicked the previous email.
With these new indicators, it is much harder to find a basic data structure. Simple rules no longer suffice, especially as there can hardly be a one-size-fits-all rule in this example. So, we need a statistical model that will supply, for each individual, the probability that (s)he will click the new promotional link on the basis of his/her criteria.
Machine learning algorithms are enhanced by significant quantities of data as opposed to human beings who find the study more complicated by them.
For example, if the number of lines exceeds 100 000, or 100 000 000, it is extremely difficult, if not impossible, to manually detect an underlying structure between individuals and variables. In this case, machine learning will try to apply statistical modeling methods to this very big set of data, to find the structure that gives the best results, i.e. the one which will give the lowest error rate.
Machine learning, combined with recent big data methods, enables increasingly large volumes of data sets of observations and variables to be processed.
The most well-known statistical modeling algorithms include: linear regression, logistic regression, classification and regression trees, factorial analysis, support vector machine and neural networks. There are also many ways of combining these methods to find a better one: boosting, vote, forest, and so on.